在之前的文章中,提到关于百度的搜索源码可以做哪些事情: http://www.zhangte.org/python/125.html
这里实践一下这个完整的过程
首先,爬虫部分不说,各种实现方式都可以,核心就在于,要把百度的搜索结果完整的保存下来! 我这里暂时以百度Json版的结果为例,比如这样:
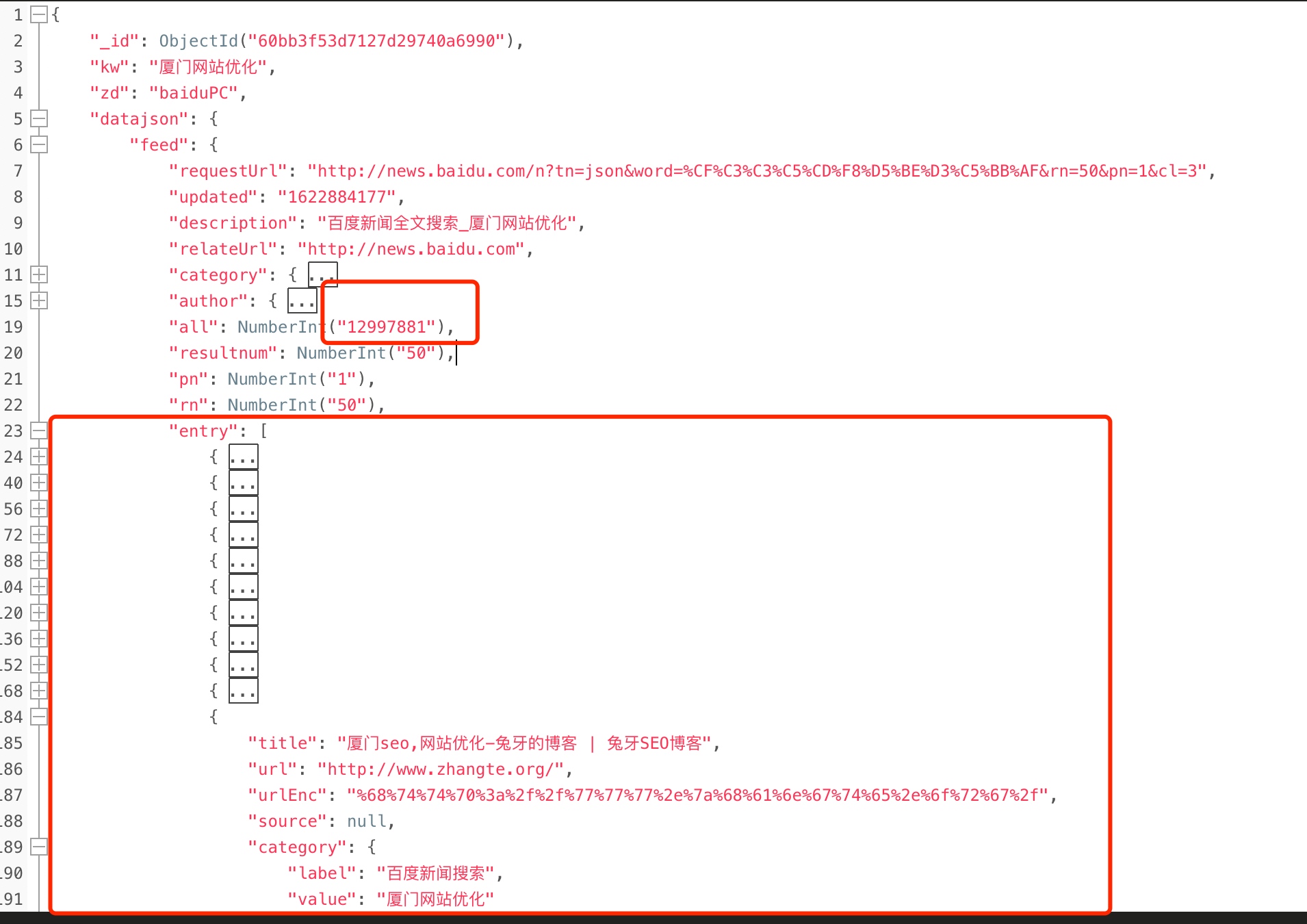 这里圈起来的核心数据:
这里圈起来的核心数据:
- 一个是搜索量
- 一个是排名结果(一条一行,共50条)
其实这样保存,爬虫也方便,查询也方便,何乐不为,而且想干嘛就干嘛,自由灵活度又高...,而且不需要频繁请求百度,对ip资源也是一种保护,难道不是吗....
下面开始进入正题... 不难看出,我的博客排名是在11位,那么如何才能搜索到排名?
kw = "厦门网站优化"
domain = "zhangte.org"
table.aggregate([{"$unwind": "$datajson.feed.entry"},
{"$match":
{'kw': {'$regex': f'^{kw}$', '$options': 'i'}, # 这是绝对包含,但是不包含大小写
'datajson.feed.entry.url': {'$regex': domain},
},
},
{'$project': {'_id': 0}} # 对结果的显示字段过滤
]).next()
这样即可返回排名
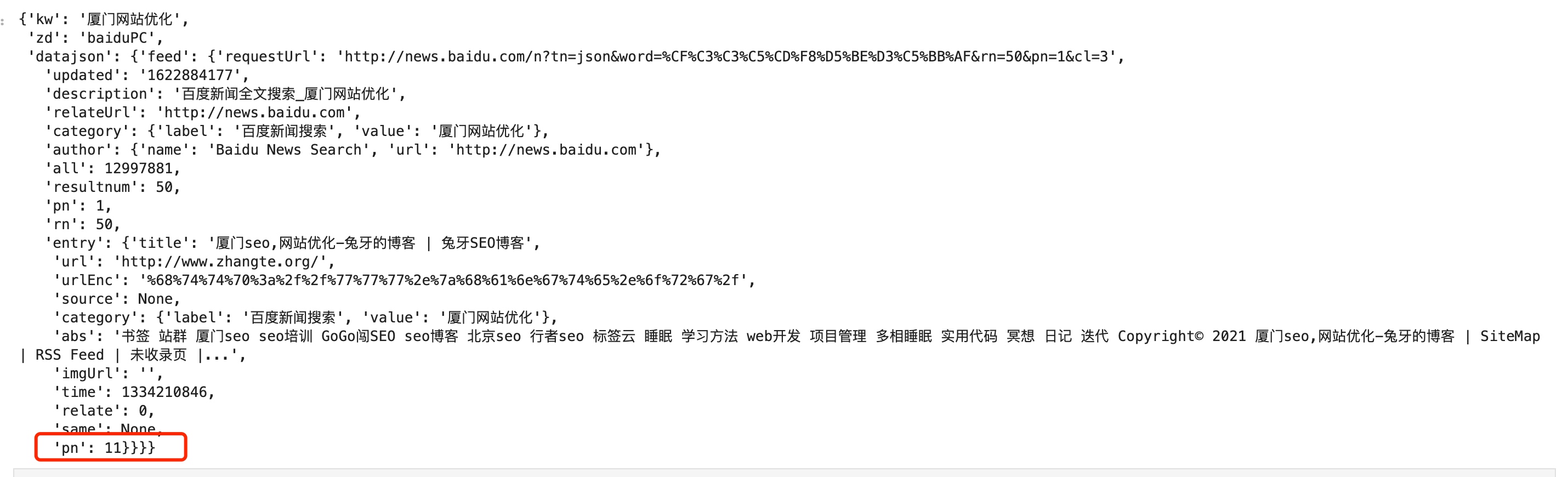 然后正常的python取值即可
然后正常的python取值即可
rank_data["datajson"]["feed"]["entry"]["pn"]
那么,既然都是拿搜索结果了,也可以这么利用,比如我要查一下www.zhangte.org这个域名,在我这个词库中有多少个词有排名,就可以这样
list(myclient["baidurankdata"]["baidu_rank_qidian"].aggregate([{"$unwind": "$datajson.feed.entry"},
{"$match":{
'datajson.feed.entry.url': {'$regex': domain},
},
},
{'$project': {'_id': 0,'kw':1,'datajson.feed.entry':1}} # 对结果进行过滤
]))

那么至于如何做数据统计分析,自然要结合pandas了,只要这样即可实现一键转表格...(2行代码)
from pandas import DataFrame
DataFrame(table_name.find({"kw":kw}).next()["datajson"]["feed"]["entry"])
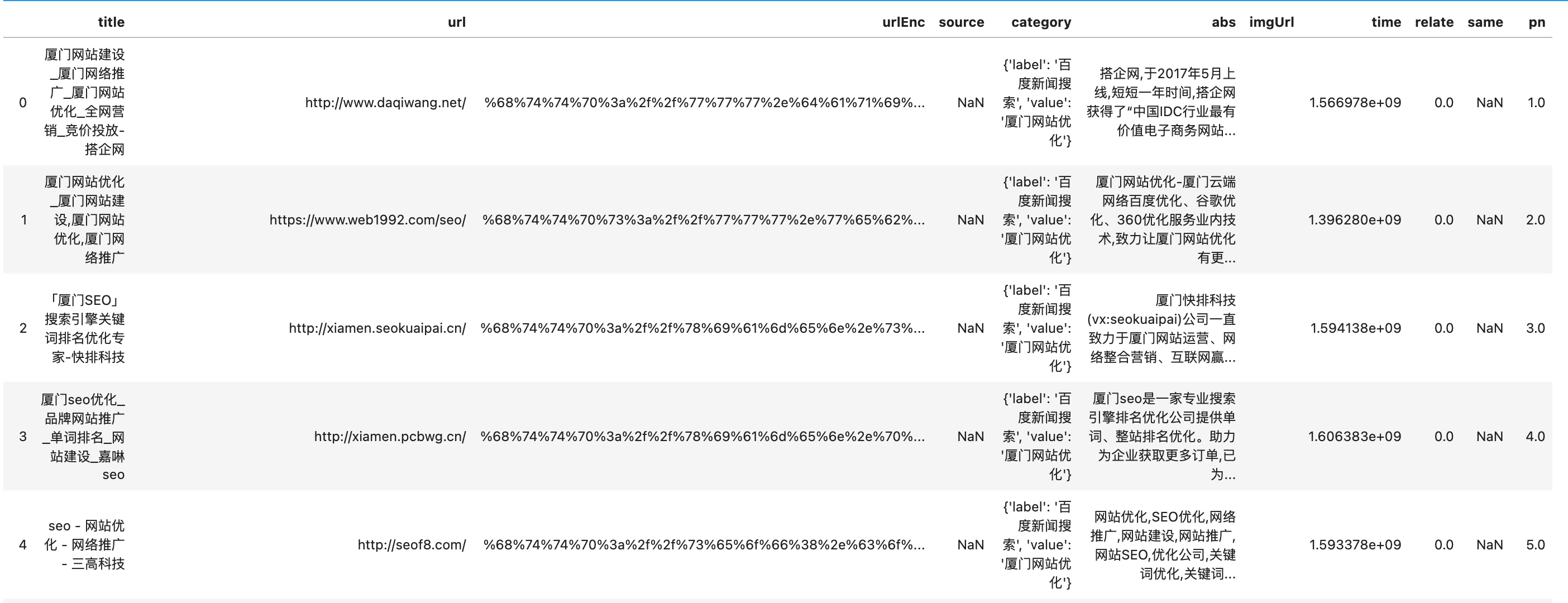 然后剩下的就借助强大的pandas进行愉快的数据分析吧....
然后剩下的就借助强大的pandas进行愉快的数据分析吧....
本文关键词: | Mongodb
转载请注明链接 : http://www.zhangte.org/seo-sem/127.html
度娘请收录下列优质文章: